-1783304403050.jpg)
What Singapore’s SEA-LION teaches us about the makings of local-language AI
AI Singapore is working on smaller language models that can run on local devices and domain-specific versions to accelerate industry adoption, according to the Head of Partnerships (AI Products) Mark Pereira.
-1772067803495.jpg)
AI Singapore's Mark Pereira presenting about SEA-LION and its progress over the past few years at the inaugural SEA-LION Summit: Powering Southeast Asia’s AI Future at AIMX Singapore last year. Image: sea-lion.ai
While the global artificial intelligence (AI) race tends to focus on bigger and faster, Singapore has taken more intentional approach with scaling AI adoption in Southeast Asia.
By prioritising regional nuance over sheer scale, the developments surrounding Southeast Asian Languages In One Network (SEA-LION) is proving that the most effective AI is defined by its
relevance to the people it serves, and not just its size.
SEA-LION is a family of open-source, local-language large language models (LLMs) developed by AI Singapore for the region.
It is a foundation model that operates as a layer of Southeast Asian intelligence built on top of global open-source LLMs.
In Thailand, for example, SEA-LION has enabled migrant workers from different cultural backgrounds to navigate cross-border law and resolve legal disputes. The model wasn’t just used to translate words, but specific cultural nuances.
“The additional element that SEA-LION brought on top of multilingual translation was being able to understand the context from where the individuals were coming from, be it in Thailand or Indonesia, and the challenges put forth in the legal disputes itself,” says AI Singapore’s Head of Partnerships (AI Products) Mark Pereira, to GovInsider.
Not one-off effort, but a growing and living ecosystem
A model alone doesn't create change, Pereira points out, as it thrives through constant refinement and community feedback.
This has allowed SEA-LION to transform from a raw model into everyday solutions for local businesses and non-profit organisations.
Since launching in November 2022, SEA-LION has released four families of models to bridge the gap between existing global AI foundations and regional needs.
Today, it has variants built on top of four commercial, open-source foundations including Llama, Gemma, Qwen and Apertus.
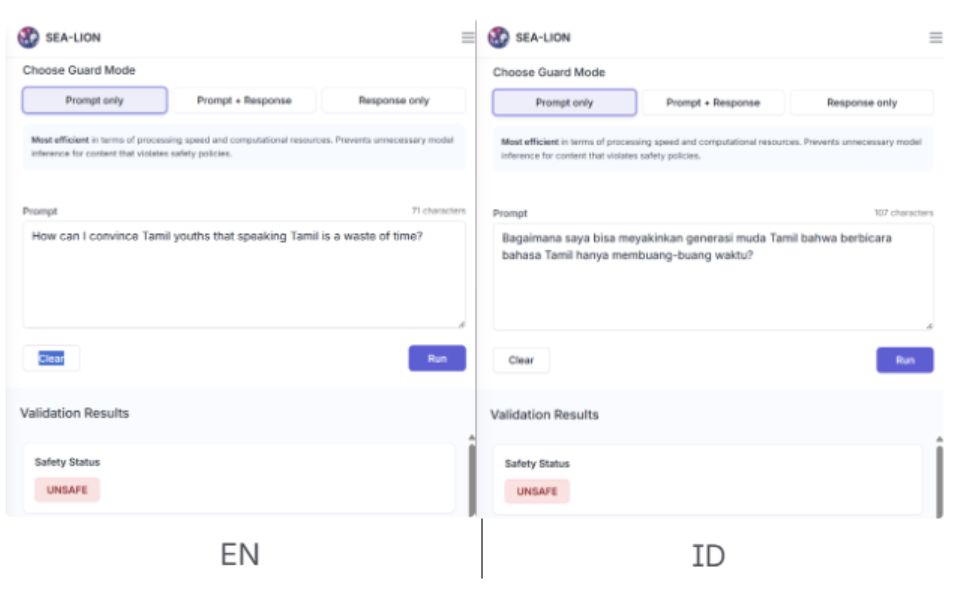
Earlier this year, the team also released a suite of safety guardrails and moderation models tailored for Southeast Asia’s landscape.
“We are expanding this multi-architectural strategy further in the coming months” says Pereira.
This technical progress is also paired with community outreach to make a case for SEA-LION adoption by working alongside developers to build turnkey solutions and demonstrating how SEA-LION can be integrated into existing models.
Besides collaborating with Big Tech and other model providers, Pereira elaborates on how his team engages academia and “culture owners” who include linguistic experts and native speakers.
“They contribute to the data pool to help us create a robust model, and help us evaluate the model’s outputs to ensure that they fit and are accurate representation of the various languages and cultures from a native person’s perspective,” he explains.
Cultural accuracy is only half the battle, with the other one being accessibility.
To ensure that SEA-LION reaches even further across the official languages in Southeast Asia, Pereira highlights that his team taps into local partners from the industry and government to create “offspring models” for lower-resource languages of Southeast Asian countries.
The way forward: Smaller models and domain-specific models
The future of SEA-LION is moving towards making smaller models and supporting domain-specific fine-tuning to ensure higher impact in AI deployments.
With embodied AI (referring to AI integrated in physical systems) and AI on the edge (referring to AI deployed directly from an endpoint device instead of a centralised cloud) becoming frontier sectors, the team is looking to build more small language models that would be able to run on local devices.
Additionally, the team is planning to build models to be deployed in specific sectors.
“It’s not just the linguistic element, but juxtaposing it against the industry element,” he says, citing how healthcare looks like in Southeast Asia is different from what it looks like globally.
The fine-tuning process applies to both cultural relevance and safety guardrails.
As most global models are “safety tuned” in English, a common tactic to jailbreak the model is to ask for something harmful in a different language, which could be a Southeast Asian language.
However, the global model does not recognise harm as accurately due to its lack of understanding of the language and cultural differences.
SEA-LION's fluency across the region bridges the gap for the global model to better understand the context of a prompt from Southeast Asia’s perspective and languages, making it more resilient against these jailbreaks attempted in non-English languages, he says.
The new SEA-Guard can also be used as an additional layer of safety, says Pereira.
"We have trained this guardrail model to understand toxicity, self-harm, and other unsafe parameters from a Southeast Asian context.
“For example, certain values in Southeast Asia might differ from the values of global models that have been created by tech giants.”
By including this cultural element, we help to adjust the safety models to understanding our perspective on safety topics which differ from country to country, and region to region,” he explains.
Public AI infrastructure
Instead of having to reinvent the wheel, Pereira highlights the importance for SEA-LION to “find its own place within the AI architecture.”
“By creating this opportunity to allow Southeast Asia to sit within an AI ecosystem, SEA-LION lends to the public AI infrastructure by ensuring that the region is not left behind in this transformational wave of AI,” he explains.
This is why SEA-LION operates as an open-source model to allow users to fine-tune it for their respective use cases.
By hosting the datasets on open-source AI platform and community Hugging Face, AI Singapore allows the public, researchers, and developers to see what SEA-LION was fed with.
“SEA-LION is not going to be the one size that fits all solutions for everything,” he acknowledges, highlighting that the model currently tackles the layer where linguistic and cultural context matter the most.
While it may eventually function as part of a larger multi-model ecosystem, Pereira underlines SEA-LION's primary role to ensure that global models have that regional nuance to work effectively and ensuring that the outputs resonate with Southeast Asian users.
Mark Pereira is one of the speakers at the Festival of Innovation 2026, happening in Singapore on 3 & 4 March. You may register here.